1. Logstash 개요
- ELK stack(Elasticsearch, Logstash, Kibana의 세 가지 프로젝트로 구성된 스택을 의미하는 약어) 중 하나
- 데이터 수집과 가공기능을 제공하는 ETL(Extract(추출), Transform(변환), Load(적재)의 약어) Tool
- 로그(비정형 데이터)를 수집 및 분석하고 시스템에서 인식 가능하도록 정제하는 작업에 용이
- 데이터 수집 - 데이터 가공(Logstash) - 데이터 저장(ES) - 분석 및 시각화(Kibana)
2. Logstash의 기능
2.1 Pipeline(파이프라인)

- 비정형 데이터를 입력받아 실시간으로 변경하고 이를 타 시스템에 전달하는 역할 : Logstash의 핵심 부분
- 비정형 데이터(Unstrctured data)란?
미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보(예, file, http, tcp 등)
- 자체적으로 내장되어 있는 메모리와 파일 기반의 Queue(큐)를 사용
- 메모리는 휘발성이기 때문에 문제 발생 시 1회 전송을 보장하기 위한 별도의 큐 보유
- 큐의 종류
| Queue | 설명 |
| Memory Queue | - 기본적으로 사용하는 큐 - 속도가 빠르고 용량이 적지만, 장애 발생 시 데이터가 유실됨 |
| Persistent Queue | - Disk 내부의 큐에 이벤트를 저장하여 시스템 장애 시 데이터 손실 방지 가능 - Memory 큐에 비해 처리 속도가 10% 정도 느리고, 용량이 큼 |
| Dead letter Queue | - 처리할 수 없는 이벤트에 대한 Disk 저장소를 제공하여 사용자가 이벤트 평가 가능 |
- 입력(input, 필수 구성 요소), 필터(filter, 선택 요소), 출력(output, 필수 구성 요소) 순으로 구성
- [파이프라인의 구성요소 상세]
2.1.1 Input(입력)
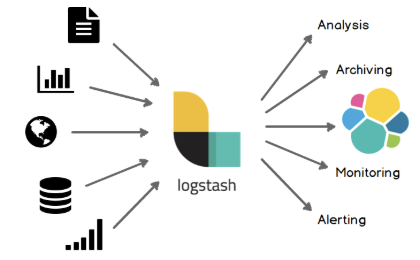
- 파이프라인의 가장 앞부분에 위치
- 소스 원본으로부터 데이터를 입력받는 단계 : 직접 받을 수도 있지만, 서버를 열어서 받아들일 수도 있음
- 자주 사용하는 입력 플러그인
| 플러그인 | 설명 |
| file | 리눅스의 tail -f 명령처럼 파일을 스트리밍하여 이벤트를 읽어 들인다. |
| syslog | 네트워크를 통해 전달되는 시스로그를 수신한다. |
| kafka | 카프카의 토픽에서 데이터를 읽어 들인다. |
| jdbc | JDCB 드라이버로 지정한 일정마다 쿼리를 실행해 결과를 읽어들인다. |
2.1.2 Filter(필터)
- 비정형 데이터를 유의미한 정형화 데이터로 가공
- 데이터 분석을 위한 구조를 잡아줌
- 자주 사용하는 필터 플러그인
| 플러그인 | 설명 |
| grok | - grok 패턴을 사용해 메시지를 구조화된 형태로 분석 - grok 패턴은 일반적인 정규식과 유사 |
| dissect | - 간단한 패턴을 사용해 메시지를 구조화 된 현태로 분석 - grok에 비해 조금 낮은 자유도 / 빠른 처리 속도 제공 : 정규식 미사용 |
| mutate | 필드명을 변경, 문자열 처리 등 일반적인 가공 함수들을 제공 |
| date | 문자열을 지정한 패턴의 날짜형으로 분석 |
2.1.3 Output(출력)
- 파이프 라인의 입력과 필터를 거쳐 가공된 데이터를 지정한 대상으로 내보내는 단계
- 자주 사용하는 출력 플러그인
| 플러그인 | 설명 |
| elasticsearch | bulk API를 사용해 엘라스틱서치에 인덱싱을 수행 |
| file | 지정한 파일의 새로운 줄에 데이터를 기록 |
| kafka | 카프카 토픽에 데이터를 기록 |
2.2 Codec(코덱)
- 입력/출력/필터와 달리 독립적으로 동작하지 않고 입력과 출력 과정에 사용되는 플러그인
- 입/출력 시 메시지를 적절한 형태로 변환하는 스트림 필터
- 자주 사용하는 코덱 플러그인
| 플러그인 | 설명 |
| json | 입력 시 json 형태의 메시지를 객체로 읽어 들인다 |
| plain | 메시지를 단순 문자열로 읽어들인다 : 출력 시 원하는 포맷 지정 가능 |
| rubydbug | - 설정 테스트 및 파이프라인 설정 오류 디버깅 목적으로 사용 - Ruby 언어의 해시 형태로 이벤트 기록 - 입력 시엔 미사용 |
2.3 다중 파이프라인
- 하나의 로그스태시에서 여러 개의 파이프라인을 동작하는 방법
- 하나에 서버에 존재하는 여러 로그를 하나의 Elasticsearch에 전송하는 방법
1) 로그스태시를 여러 개 실행 : 독립적인 JVM 인스턴스이기 때문에 모니터링과 관리가 어려움
2) 조건문을 두어 분리 : 필터 처리가 복잡
3) 다중 파이프라인을 활용 : 하나의 로그 스태시에서 여러 개의 파이프라인을 동작 : 가장 용이하고 효율적
- 기본적인 파이프라인 설정 yml
| yml | 설명 |
| pipeline.id | 파이프 라인의 고유ID |
| path.config | 파이프 라인 설정 파일의 위치 |
| pipline.workers | 필터와 출력을 병렬로 처리하기 위한 워커 수 |
| pipline.batch.size | 입력 시 하나의 워커 당 이벤트를 동시 처리할 최대 개수 |
| queue.type | 파이프 라인에서 사용할 큐의 종류 |
2.4 모니터링
- 로그스태시가 제공하는 api
- 9600 포트로 로그스태시가 제공하는 REST API 사용 가능
3. Logstash의 특징
3.1 플러그인 기반
- 로그스태시의 파이프라인을 구성하는 각 요소들은 전부 플러그인 형태로 제작
- 플러그인 개발을 위한 프레임워크를 포함하고, 플로그인을 관리할 수 있는 기능도 제공
3.1 모든 형태의 데이터 처리
- 기본 제공되는 플러그인들의 조합만으로 대다수의 데이터 소스에서 JSON,XML 등의 구조화된 텍스트 뿐만 아니라 다양한 형태의 데이터를 입력받아 가공한 후 저장 가능
3.1 성능
- 자체적으로 내장되어 있는 메모리와 파일 기반의 큐를 사용하여 높은 처리속도와 안정성
- 인덱싱할 도큐먼트의 수와 용량을 종합적으로 고려해 벌크 인덱싱을 수행
- 파이프라인 배치 크기 조정을 통해 병목현상 방지 및 성능 최적화 가능
3.1 안정성
- ES의 장애 상황에 대응하기 위한 재시도 로직 내장
- 발생 오류 도큐먼트 보관하는 데드 레터 큐 내장
[출처]
https://blog.naver.com/PostView.nhn?blogId=wideeyed&logNo=222153700165
https://velog.io/@fj2008/Logstash-%EB%9E%80#%ED%8C%8C%EC%9D%B4%ED%94%84-%EB%9D%BC%EC%9D%B8
'초보 개발자의 스터디룸' 카테고리의 다른 글
| [gRPC] gRPC 기초적인 추가 정보 2. 스트리밍 방식, 개발 순서 (0) | 2023.01.31 |
|---|---|
| [gRPC] gRPC란? 1. 개요, 특징, 사례 (0) | 2023.01.31 |
| [Elastic Search] 엘라스틱서치란? 3. 장/단점, ES vs RDBMS (0) | 2023.01.06 |
| [Elastic Search] 엘라스틱서치란? 2. 역 색인(Inverted Index) (0) | 2023.01.06 |
| [Kafka] 아파치 카프카란? 2. 개요, 사용 이유, 데이터 모델 (0) | 2023.01.06 |