
운동하는 개발자의 메모장
[Kafka] 아파치 카프카란? 2. 개요, 사용 이유, 데이터 모델 본문
카프카 게시글
1. Apache Kafka 개요
1.1 Apache Kafka란?
- 2011년 링크드인에서 개발 및 오픈소스 공개, 현재는 아파치 공식 오픈소스
- 애플리케이션 간 대용량 메세지 교환 목적으로 사용되는 메세징 Queue 시스템
- 실시간 비동기 처리 : 병렬식 테스크 수행, 작업의 종료에 관계없이 다음 동작 실행 가능
- 확장성이 용이한 분산 스트리밍 플랫폼
1.2 Apache Kafka의 장점
1.2.1 확장성(분산 시스템)
- 클러스터에 브로커를 추가하는 방식
- 여러 개의 브로커로 구성된 클러스터는 개별 브로커 장애를 처리하여 사용자에게 지속적인 서비스 제공 가능
1.2.2 고성능(데이터 전송 효율 증가)
- 프로듀서와 컨슈머가 브로커를 통해 데이터를 주고받을 때 한번에 대량의 데이터를 주고받도록 설계
- 파티션과 컨슈머의 개수를 동일하게 늘려 병렬처리
- End to end 방식은 데이터 전송 시 한 건씩 처리하여 복잡도가 올라가면 서버에 부담이 크다
1.2.3 영속성
- 프로듀서에 의해 브로커로 전송된 메시지는 토픽의 파티션에 저장되고, 각 메시지들은 Segment(세그먼트, 로그 파일의 형태)로 브로커의 로컬 디스크에 저장
- 페이지캐시 영역에 데이터를 저장하여 입/출력 속도 보완
페이지 캐시 : 처리한 데이터를 메인 메모리 영역(RAM)에 저장해서 가지고 있다가, 다시 이 데이터에 대한 접근이 발생하면 Disk에서 I/O 처리를 하지 않고 메인 메모리 영역의 데이터를 반환하여 처리할 수 있도록 함
- 컨슈머가 데이터를 가져가도록 토픽 보존
- 잔여 메모리를 쓰기 때문에 카프카 서버에 타 애플리케이션을 함께 사용하는 것은 지양
3. Kafka 사용 이유
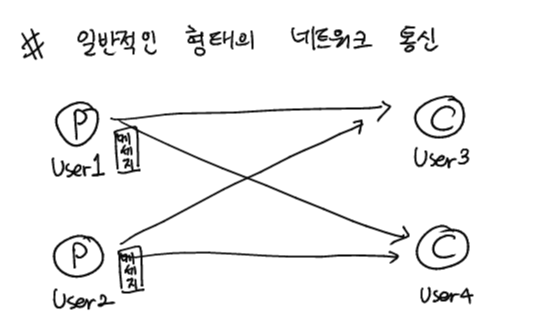
2.1 Kafka 도입 전 (end to end)
- 애플리케이션 간 데이터 전송 시 직접 연결해서 전송
- 시스템의 규모가 커지면서 애플리케이션의 개수가 늘어나게 되면서 데이터 전송 관계가 복잡
- 특정 애플리케이션에 장애가 발생할 경우, 연결된 특정 애플리케이션에조차 영향을 끼치는 문제 발생 (데이터가 유실 가능)
2.2 Kafka 도입 후 (pub/sub방식)
- 애플리케이션 간 의존도 감소
- Producer에서 Kafka의 Topic(메시지 저장소)에 데이터를 저장
- Consumer에서 원하는 Topic의 데이터를 가져가는 형태의 시스템
- 중앙에 메시징 시스템 서버를 두고 메시지를 보내고 받는 형태의 통신 : pub/sub방식

3. Kafka 데이터 모델


Producer -> Broker 1 - Topic A (Partition 0 : Partition Leader) -> Consumer
Producer -> Broker 1 - Topic A (Partition 1 : Broker 2 - Topic A, Partition 1 Copy) -> Consumer
Producer -> Broker 2 - Topic A (Partition 0 : Broker 1 - Topic A, Partition 0 Copy) -> Consumer
Producer -> Broker 2 - Topic A (Partition 1 : Partition Leader) -> Consumer
'초보 개발자의 스터디룸' 카테고리의 다른 글
| [Elastic Search] 엘라스틱서치란? 3. 장/단점, ES vs RDBMS (0) | 2023.01.06 |
|---|---|
| [Elastic Search] 엘라스틱서치란? 2. 역 색인(Inverted Index) (0) | 2023.01.06 |
| [Elastic Search] 엘라스틱서치란? 1. 관련 용어 정리, 특징 (1) | 2023.01.05 |
| [Kafka] 아파치 카프카란? 1. 구성요소, 연산방식, 관련용어 (0) | 2023.01.04 |
| [GitHub] 이클립스 깃허브 연동 (0) | 2022.12.10 |



